
”大数据 hadoop HDFS 数据仓库 MapReduce“ 的搜索结果
通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍。基本涵盖了Hadoop分布式平台的所有技术核心。从体系架构到数据定义到数据存储再到数据...
文章目录概述HadoopHDFSHBase实现原理Regin服务器原理HBase安装与使用...大数据是由结构化和非结构化数据组成的 10%的结构化数据,存储在数据库中 90%的非结构化数据,它们与人类信息密切相关 大数据技术的不同层面

大数据组件是解决大数据的关键组件之一,在Hadoop生态系统中占据着至关重要的地位,它包括了HDFS、MapReduce、Hive等等一系列框架和工具。本文将会通过主要分析HDFS、MapReduce、Hive三个大数据组件的特点和架构,并...
想学好大数据,首先要了解他的基础,所以,我们需要先了解HDFS和Hadoop以及MapReduce。 首先大家思考一个问题:如何合理的存储10T的电信通话记录? 下面给大家展现一个图片: 入的知识点: 元数据:描述数据...
在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序; 2.数据清洗案例实操 2.1:需求 去除日志中字段长度小于等于...
Hadoop是大数据开发的重要框架,是一个由Apache基金会所开发的分布式系统基础架构,其核心是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算,在Hadoop2.x时 代,增加 了Yarn,Yarn...

要运行这个实例,必须先...大数据Hadoop之——数据仓库Hive 【实例代码如下】 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2022/5/8 10:35 # @Author : liugp # @File : Data2HDFS.py """ # pip instal

本文介绍了Hadoop的基本概念,包括HDFS,MapReduce和YARN。我们还演示了如何使用Java编写MapReduce作业和如何使用Hive进行数据分析。这些技术可以帮助处理和分析大规模数据集,从而实现数据驱动的决策和业务增长。

上一篇我搭建完成了Linux系统以及配置,本篇文章进行我的项目回顾和Hadoop环境准备什么是网站日志?网站,或者说web服务器在运行过程中如果有用户访问了我们的服务器,它会把信息以文本形式自动记录下来,这个文件...
通过这一阶段的调研总结,对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍。基本涵盖了Hadoop分布式平台的所有技术核心。从体系架构到数据...
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
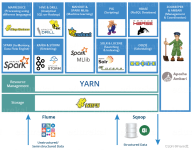
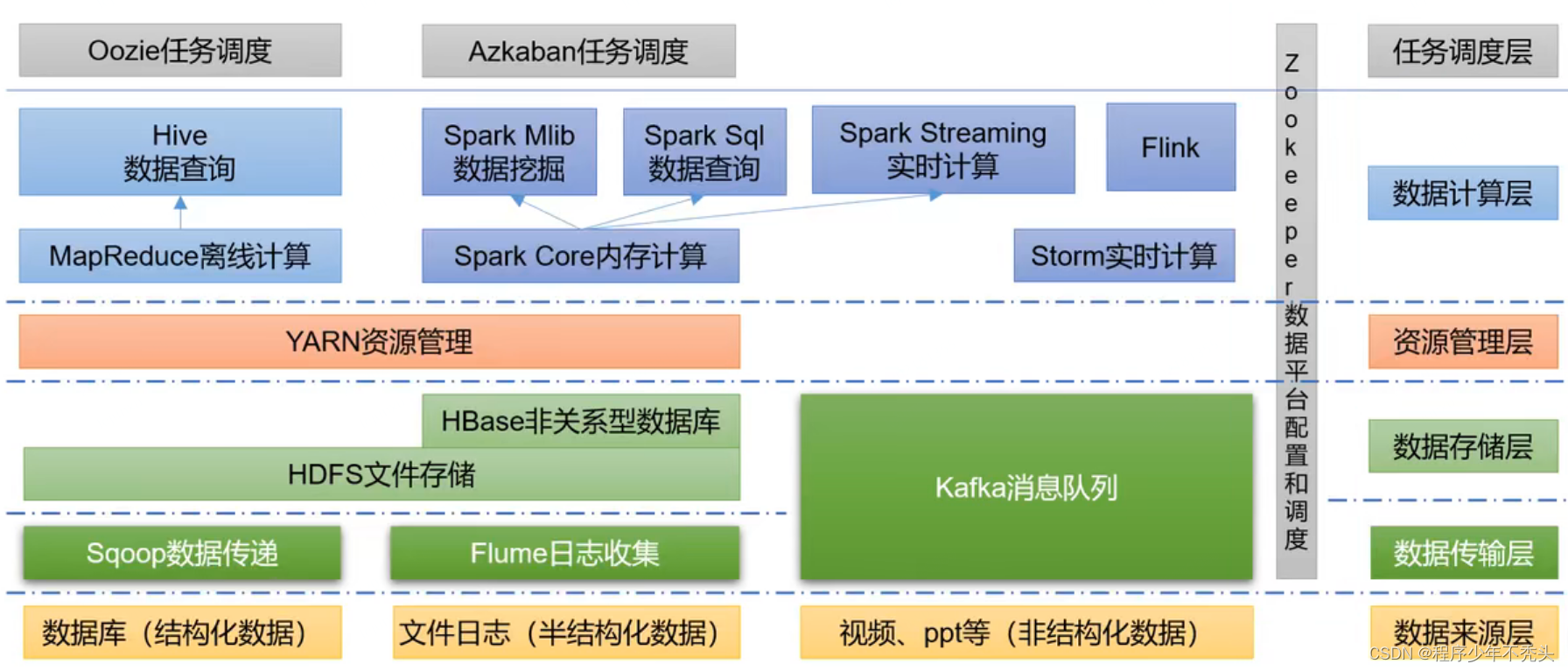
大数据生态知识体系
一、概述(部署请跳到第二节) 1.大数据的由来 随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,...-大数据指无法在一定时间范围内用常规工具进行捕捉,管理和处理的数据集合 ...
今天我们常说的大数据技术,其实起源于 Google 在 2004 年前后发表的三篇论文,也就是我们经常听到的大数据 “三驾马车”,分别是分布式文件系统 GFS、大数据分布式计算框架 MapReduce 和 NoSQL 数据库系统 BigTable...
大数据篇 | Hadoop、HDFS、HIVE、HBase、Spark之间的联系与区别
一、简介 Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发... Hadoop对应于Google三驾马车:HDFS对应于GFS,即分布式文件系统,MapReduce即并行计算框架,...

要了解什么是Hadoop,我们必须首先了解与大数据和传统处理系统有关的问题。前进,我们将讨论什么是Hadoop,以及Hadoop如何解决与大数据相关的问题。我们还将研究CERN案例研究,以突出使用Hadoop的好处。 在之前的...


福建师范大学精品大数据导论课程系列 (5.7.1)--4.4 一种基于Hadoop的数据仓库之一.pdf 福建师范大学精品大数据导论课程系列 (5.8.1)--4.4 一种基于Hadoop的数据仓库之二.pdf 福建师范大学精品大数据导论课程系列 ...
福建师范大学精品大数据导论课程系列 (5.7.1)--4.4 一种基于Hadoop的数据仓库之一.pdf 福建师范大学精品大数据导论课程系列 (5.8.1)--4.4 一种基于Hadoop的数据仓库之二.pdf 福建师范大学精品大数据导论课程系列 ...
推荐文章
- 1N5819-ASEMI轴向肖特基二极管1N5819-程序员宅基地
- 把maven的setting配置文件改为需要jdk版本_<profile> <id>jdk-1.4</id> <activation> <jdk>1.4</-程序员宅基地
- 使用matlab进行DBscan聚类_dbscan聚类分析图用什么软件-程序员宅基地
- 探秘技术新星:BBS_admin - 一个现代化的论坛后台管理系统-程序员宅基地
- 【译】JavaScript 开发者年度调查报告-程序员宅基地
- 神仙级渗透测试入门教程(非常详细),从零基础入门到精通,从看这篇开始!_网络渗透技术自学-程序员宅基地
- 多个protocbuf版本切换_protobuf调整版本-程序员宅基地
- msf+cobaltstrike联动(一):把msf的session发给cobaltstrike-程序员宅基地
- C语言--编写程序,输入一个整数,判断它能否被3,5,7整除_编程序实现功能:输入一个整数,判断其是否能同时被3、5、7整除。能被整除则输出“y-程序员宅基地
- 数据技术之Hadoop(HFDS文件系统)-程序员宅基地